目录
Disco:Google 把“浏览网页”变成“搭应用”的那一步
Disco 是 Google 的一次试探:它想改变我们“用互联网做事”的方式——不再只是打开网页、读完、关掉,而是把网页里的信息直接拼成一个能用的工具。 当你研究一个主题、计划一次旅行,或给孩子备一堂科学课时,浏览器里很快就会堆满标签页:攻略、地图、餐厅、价目表、研究文章……信息越多,越难整合。过去两年,生成式 AI 多数时候做的是“把问题变成更好的文本”。但 Google 在 11 月把方向往前推了一步:不只生成内容,还要生成界面——让模型根据你的任务,现场做出一个可交互的小工具,把理解、操作、决策放到同一个 UI 里完成。
这条路线在产品侧刚落地不久:
- Gemini App 里出现了 Dynamic view 与 Visual layout 两个“生成式界面(generative interfaces)”实验;
- Google Search 的 AI Mode 也开始为查询即时生成带交互工具和模拟器的动态布局。而 12 月 Google Labs 推出的 Disco,则把这套思路带回浏览器:把“看很多网页”直接变成“生成可用的工具界面”。推动这一点的核心功能,就是 GenTabs。
Generative UI:从“生成文本”到“生成界面”
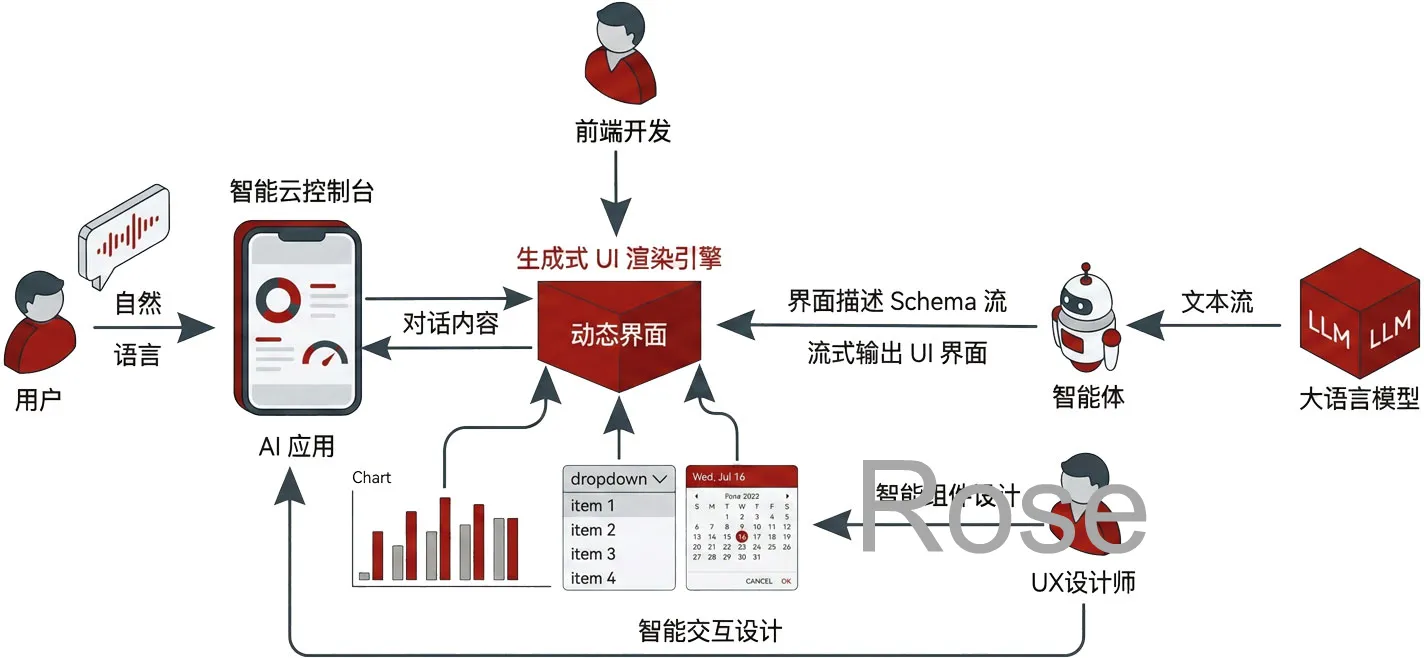 Google Research 把这类能力叫做 Generative UI(生成式 UI):模型生成的不只是“答案内容”,还会连同呈现方式一起生成——它可以按你的指令即时设计、编码并渲染一个交互界面(网页、工具、模拟器、游戏、小应用等),而不只是给你一段 Markdown 长文。
Google Research 把这类能力叫做 Generative UI(生成式 UI):模型生成的不只是“答案内容”,还会连同呈现方式一起生成——它可以按你的指令即时设计、编码并渲染一个交互界面(网页、工具、模拟器、游戏、小应用等),而不只是给你一段 Markdown 长文。
这件事的价值并不玄学:很多复杂任务就是需要“可操作的结构”——表格要筛选、地图要缩放、参数要拖动、对比要切换。文字当然能解释,但很难把“下一步怎么做”写成顺手的交互。Generative UI 要做的,是把“回答”往前推成“工具”。
从工程实现上,Google 给了一个很清晰的“三件套”:
- 工具访问(tool access):让模型能调用图像生成、网页搜索等工具,生成的结果也能直接送到浏览器里展示。
- 系统指令(system instructions):用目标、规划、示例、技术规范与工具手册,把“怎样生成一个靠谱的界面”写清楚。
- 后处理(post-processing):用一组后处理器修常见问题,提升可运行性与一致性。
在 Google Research 的论文里(并配套发布了用于评测的 PAGEN 数据集)还给了一个直观结论:如果暂时不把生成速度算进去,用户更喜欢 Generative UI 的输出,而不是常见的纯文本/Markdown。它整体上仍不如人类专家设计的网站,但差距已经没那么夸张——摘要里提到,有 44% 的案例里,两者达到了“相近水平”。
在产品层面,Gemini 3 把 Generative UI 先做成了两个“生成式界面”实验:
- Visual layout:做成杂志风格的图文布局(照片 + 模块),你可以继续点、继续改,把结果往自己的偏好里收敛。
- Dynamic view:利用 Gemini 3 的 agentic coding 能力,按你的指令现场设计并编码一个定制 UI,让你通过点按、滚动、参数交互来推进任务。
在 Search 的 AI Mode 里,Gemini 3 会为查询动态生成“更合适的布局”。当它判断“做个工具更有用”时,甚至会现场写一个模拟器/计算器(比如物理模拟、贷款计算),直接嵌进结果里,同时把高质量网页链接摆在显眼位置,方便你核验来源。
A2UI:把“生成界面”变成可跨应用/跨信任边界的协议
如果说 Generative UI 更像“模型直接生成一个可运行的网页体验”,那 Google 新公开的 A2UI(Agent-to-User Interface) 更像是在补一块底座:让智能体把 UI 当作结构化消息发给宿主应用,由宿主用自己可信的组件体系来渲染。
它要解决的其实很现实:在多智能体协作里,干活的子智能体往往是远程的,甚至来自不同组织,它当然不该直接“动你的前端”。如果让它回传 HTML/JS 再塞进 iframe,会变笨重、风格割裂,安全边界也麻烦。A2UI 的做法是“像数据一样安全,像代码一样能表达”:智能体只能从客户端维护的“可信组件目录”(比如 Card、Button、TextField)里拼装界面;渲染和样式由客户端掌控,从而降低 UI 注入风险,也更容易和宿主应用保持一致。
在形态上,A2UI 用声明式 JSON(支持增量更新/流式渲染)来描述组件与数据模型,同一份 payload 可以在不同端(Web Components、Angular、Flutter 等)渲染出来。换句话说,“生成界面”不必只靠某个产品单点实现,它也可以变成一种可互操作的 UI 语言:让智能体跨应用、跨平台、跨信任边界时也能稳定地“说 UI”。
把这些连起来看,Disco 就没那么“凭空出现”了:它更像 Generative UI 在真实网页上下文里的一个试验场。浏览器天然握着“你正在看的网页与来源”,所以 Disco 才能把生成出来的界面绑回原网页,形成“浏览—拼装—操作—迭代”的循环。
什么是 Disco 与 GenTabs
- Disco 是一个实验性的浏览器体验,目标不是更快地给你“答案”,而是更快地把散落信息“组装成可操作的界面”。
- GenTabs 是由 Gemini 3 模型依据你的目标与已打开的网页标签即时生成的“小型交互式网页应用”。它不是一段文本总结,而是一个能操作的 UI:地图、行程表、价格对比、抽认卡、简易可视化等。
简单说:传统搜索更像“你去找零件”,GenTabs 更像“它帮你把零件先拼成工具”,你再边用边改。
它具体怎么用
- 你在 Disco 里创建一个“项目”,里面既有聊天(描述你的需求),也有你主动打开的普通网页标签。
- 模型读取你的目标与这些标签页,生成一个 GenTab 界面。你继续打开新网页,GenTab 会“吸收”新信息并更新界面。
- 你可以用自然语言修改界面:增加维度、调整表格、添加筛选、替换数据源……像和一个前端同事配合迭代,但无需写代码。
典型场景:
- 旅行:聚合地图、景点、餐厅与攻略,生成可交互行程规划器;你加新的店铺链接,它自动纳入。
- 学习:从多篇科普与百科页生成抽认卡或交互可视化,帮助理解人体踝关节、行星运动等。
- 生活组织:从食谱页生成周菜单;从搬家报价与清单页生成重量估算器与价格对比表。
与“AI 浏览器/助手”的不同
- 不隐藏网页:很多“AI 浏览器”把网页折叠成总结,鼓励你只在聊天框里待着;Disco 反而鼓励你打开更多网页,用真实来源做“地线”,让生成更可靠、更贴近你的真实意图。
- 结果是“界面”,不是“段落”:它交付的是能操作的 UI,而不仅是文字答案。你会更像在用一个小工具,而不是在读一段总结。
为什么这件事有意义
- 信息组织的门槛被拉低:以前要把多源信息变成可用表格或小工具,得找人做个页面或用复杂的 Notion/Sheet 工程。现在,你用自然语言即可“拼装”并迭代。
- 从“搜索到答案”走向“任务完成”:浏览器不再只是信息入口,而开始像一个任务工作台。对学习、研究、消费决策、轻量项目管理都会更顺手。
- 人机协作的循环更顺畅:人负责探索与选择来源,AI 负责界面与结构化;然后人再补充、更换来源,AI 随即更新界面(天然的双向迭代闭环)。
限制与开放问题
- 持久化与分享:GenTabs 更像“即时拼装的工具”。它是否有独立 URL、如何分享或导出到 Docs/Sheets,是官方仍在探索的方向。
- 早期粗糙性:作为实验产品,界面与功能可能不够稳定或精细。但生成内容都链接回原网页,便于核验与修正。
- 平台与可用性:当前通过等候名单开放,首发 macOS;更多平台与功能路线尚未公布。
面向产品与技术的启示
- 语义到界面:从“生成文本”到“生成可操作 UI”,意味着模型要理解任务目标、数据结构与交互意图——这会推动“生成式前端”的实践。
- 上下文图谱更真实:把“打开的标签页 + 聊天内容”作为任务上下文,比仅靠对话更贴近真实需求;也提示未来助手应主动“引导用户去浏览”,而不是替代浏览。
- 工具的颗粒度:GenTabs 的“即时、一次性、小而全”特性,适合临时任务与快速决策;当任务变复杂,如何从 GenTab 升级为可长期维护的应用,是值得探索的产品分层。
我们该如何看待它
- Disco 不一定是“下一个 Chrome”,但它把一个重要问题抛了出来:当网页内容越来越多、任务越来越复杂时,人与信息之间应不只是“问—答”,而应该是“拼装—操作—迭代”。如果说过去十年我们在信息获取上不断加速,那么接下来十年,也许是把信息“变成工具”的时代。Disco 并未给出所有答案,但朝这个方向迈了一步。
- 这和 OpenAI 的 Atlas 形成鲜明对比:Atlas 喊着要终结 Chrome 垄断,本质还是把 AI 当插件嵌进传统浏览器,难逃 “旧瓶装新酒” 的局限。最关键的是,Atlas 是在谷歌的 Chromium 开源框架上做的,所以它的创新只能停留在叠加一些表层功能;而谷歌作为架构主导者,天然手握底层主动权。尽管 Disco 目前还是实验性产品,未来落地存在不确定性,但一场围绕 AI 浏览器的全新大战,已然正式拉开序幕。
点击加入候选列表
Sources:
- 官网
- 官方介绍与首发信息
- Google Research:Generative UI 官方定义与实现框架
- Gemini App:Gemini 3 与 generative interfaces(visual layout / dynamic view)
- Google Search:Gemini 3 在 AI Mode 的 generative UI(动态布局、交互工具与模拟器)
- Generative UI 论文主页(含摘要与 PAGEN 数据集描述)
- A2UI:Google Developers Blog 官方发布
- A2UI:Google 开源仓库(规范与实现)
- A2UI
- [媒体报道与使用示例] (https://techcrunch.com/2025/12/11/google-debuts-disco-a-gemini-powered-tool-for-making-web-apps-from-browser-tabs/)
- [交互细节与产品形态讨论] (https://www.theverge.com/tech/842000/google-disco-browser-ai-experiment)
- 差异点与鼓励浏览的设计
- 社区讨论
- Atlas
- 从千问灵光 App 看生成式 UI 技术的发展
本文作者:Rose
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!